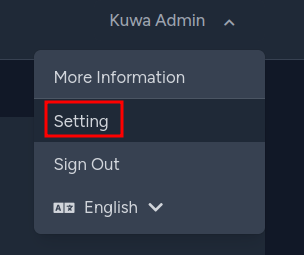
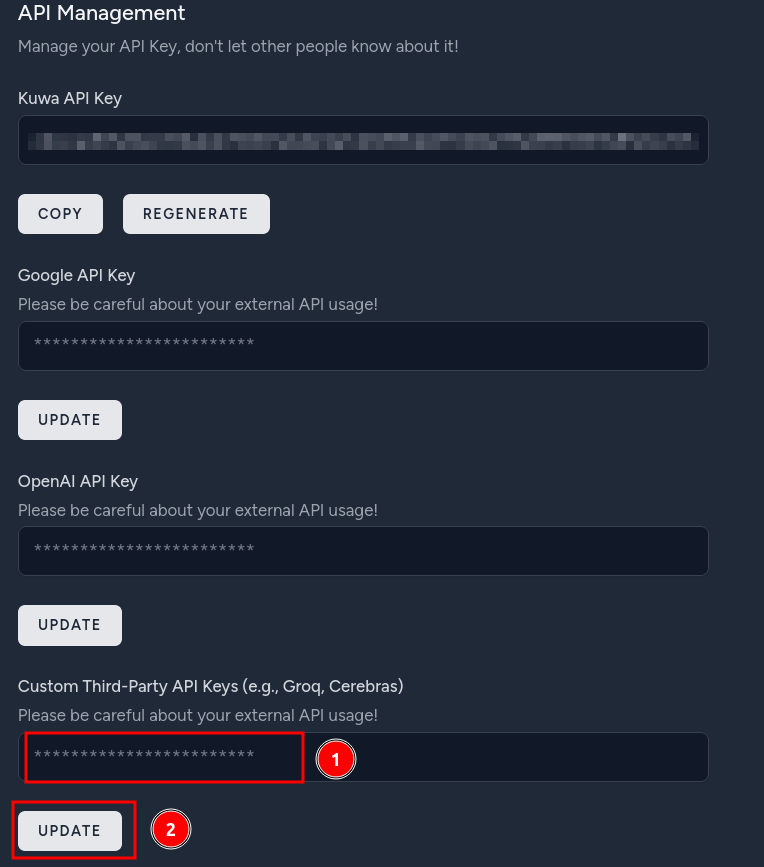
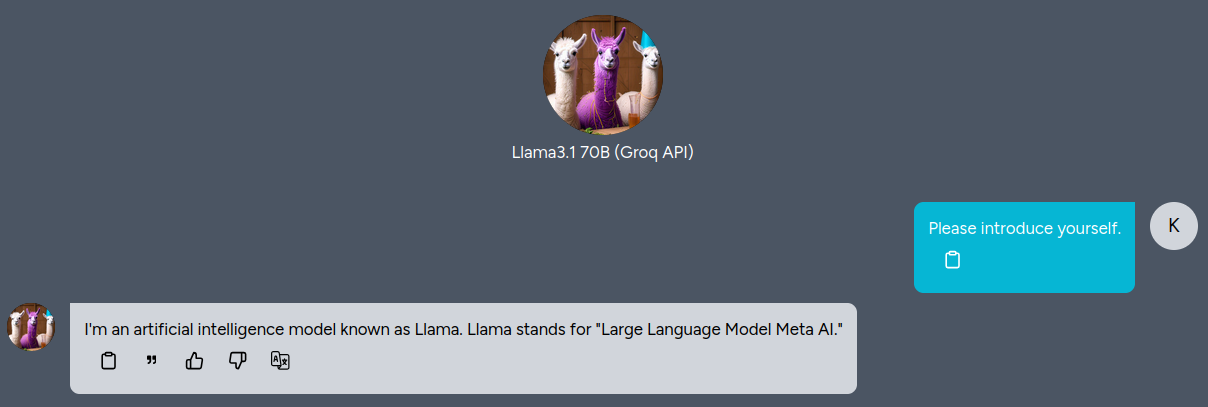
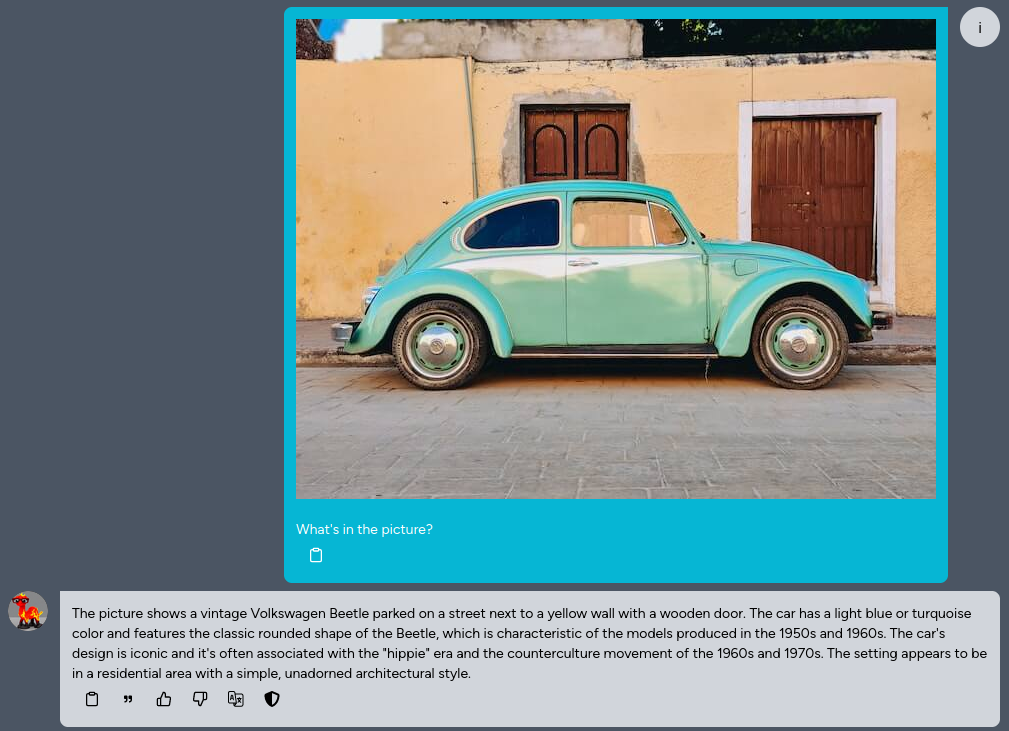
import os
import sys
import asyncio
import logging
import json
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
from kuwa.executor import LLMExecutor, Modelfile
logger = logging.getLogger(__name__)
class DebugExecutor(LLMExecutor):
def __init__(self):
super().__init__()
def extend_arguments(self, parser):
"""
Override this method to add custom command-line arguments.
"""
parser.add_argument('--delay', type=float, default=0.02, help='Inter-token delay')
def setup(self):
self.stop = False
async def llm_compute(self, history: list[dict], modelfile:Modelfile):
"""
Responsible for handling the requests, the input is chat history (in
OpenAI format) and parsed Modelfile (you can refer to
`genai-os/src/executor/src/kuwa/executor/modelfile.py`), it will return an
Asynchronous Generators to represent the output stream.
"""
try:
self.stop = False
for i in "".join([i['content'] for i in history]).strip():
yield i
if self.stop:
self.stop = False
break
await asyncio.sleep(modelfile.parameters.get("llm_delay", self.args.delay))
except Exception as e:
logger.exception("Error occurs during generation.")
yield str(e)
finally:
logger.debug("finished")
async def abort(self):
"""
This method is invoked when the user presses the interrupt generation button.
"""
self.stop = True
logger.debug("aborted")
return "Aborted"
if __name__ == "__main__":
executor = DebugExecutor()
executor.run()