

Kuwa v0.3.1 新增了基於 Stable Diffusion 圖片生成模型的 Kuwa Painter,
可以輸入一段文字產生圖片,或是上傳一張圖片並搭上一段文字產生圖片。
已知問題與限制
硬體需求
預設模型使用 stable-diffusion-2,若跑在GPU上所消耗 VRAM 如下表所示。
| 模型名稱 | VRAM需求 |
|---|---|
| stable-diffusion-2 | ~3GB |
| stable-diffusion-xl-base-1.0 | ~8GB |
| sdxl-turbo | ~8GB |
| stable-diffusion-3-medium-diffusers | ~18 GB |
已知限制
- sdxl-turbo進行img2img時會出錯
建置 Painter Executor
Windows 版啟動步驟
Windows 版預設應會自動執行 Painter Executor,若沒有執行的話請按照以下步驟執行:
- 雙擊
C:\kuwa\GenAI OS\windows\executors\painter\init.bat以產生相關執行設定 - 重開 Kuwa,或是在 Kuwa 的終端機視窗輸入
reload重新載入 Executor - 一個名為 Painter 的 Executor 應會被加入您的 Kuwa 系統中
Docker 版啟動步驟
Kuwa Speech Recognizer 的 Docker compose 設定檔位於 docker/compose/painter.yaml,可以參考以下步驟啟動:
- 將
"painter"加入docker/run.sh中的 confs 陣列 (若無這個檔案則從 run.sh.sample 複製) - 執行
docker/run.sh up --build --remove-orphans --force-recreate - 一個名為 Painter 的 Executor 應會被加入您的 Kuwa 系統中
使用 Painter
文字生圖
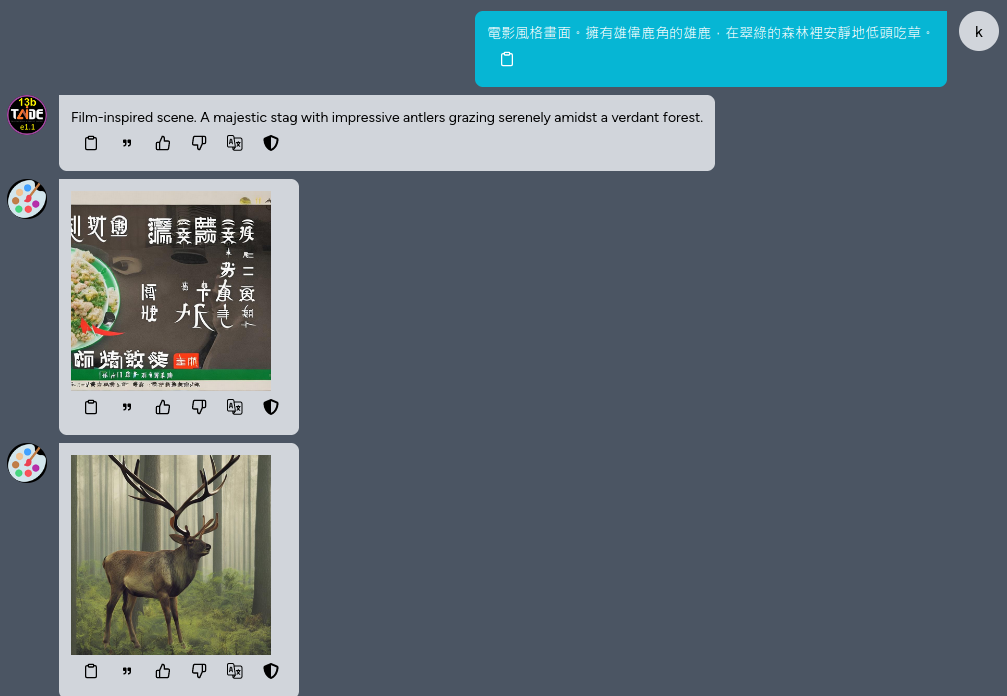
您可以輸入一段文字,讓 Kuwa Painter �替您生成一張圖片,需要注意的是原生 Stable Diffusion 模型對於中文的理解能力較差,
這時可以透過 Kuwa 的群聊與引用功能,讓其他語言模型先翻譯使用者的 Prompt ,再請 Stable Diffusion 模型產生圖片,通常會有較好的結果。
下圖第一張生成的圖片是基於原始的中文 User prompt (電影風格畫面。擁有雄偉鹿角的雄鹿,在翠綠的森林裡安靜地低頭吃草。),第二張圖是引用 TAIDE 翻譯完的 Prompt (Film-inspired scene. A majestic stag with impressive antlers grazing serenely amidst a verdant forest.) 給 Stable Diffusion 作為輸入,可以看到兩張圖的品質差異顯著。
圖生圖
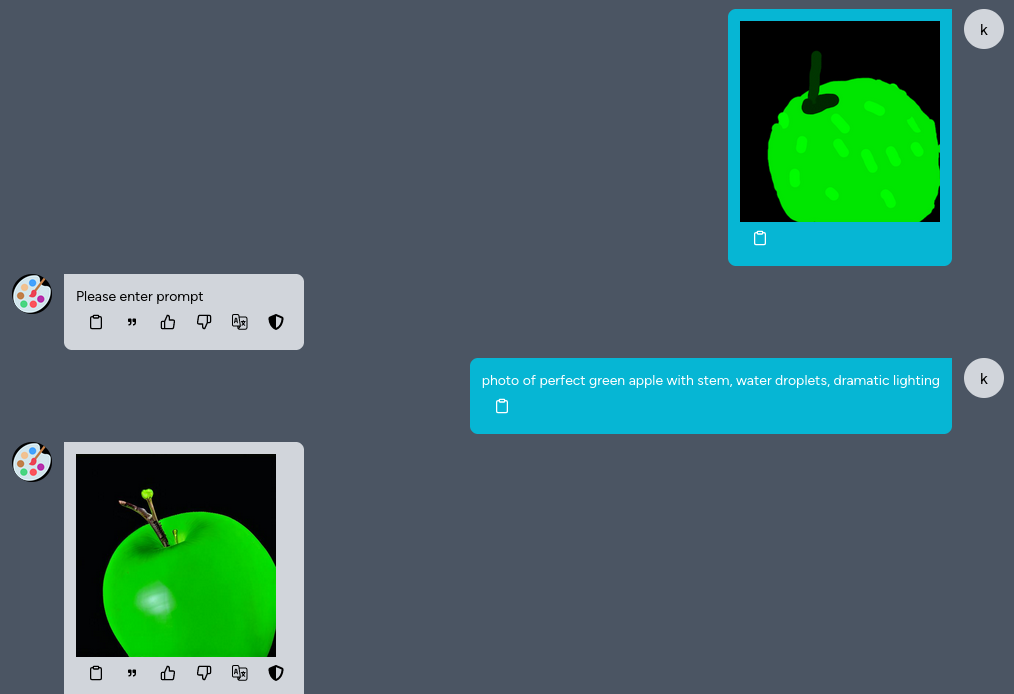
您還可以上傳一張草圖,然後描述您想要畫的東西,Kuwa Painter 就會幫您畫出來。
完整設定說明
Kuwa Painter 可以透過前端 Store 中的 Modelfile 調整生成參數,常用可調整參數如下
PARAMETER model_name stabilityai/stable-diffusion-xl-base-1.0
PARAMETER imgen_num_inference_steps 40 # The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference
PARAMETER imgen_negative_prompt "" #The prompt or prompts to guide what to not include in image generation. If not defined, you need to pass negative_prompt_embeds instead. Ignored when not using guidance (guidance_scale < 1).
PARAMETER imgen_strength 0.5 #Indicates extent to transform the reference image. Must be between 0 and 1. image is used as a starting point and more noise is added the higher the strength. The number of denoising steps depends on the amount of noise initially added. When strength is 1, added noise is maximum and the denoising process runs for the full number of iterations specified in num_inference_steps. A value of 1 essentially ignores image.
PARAMETER imgen_guidance_scale 0.0 #A higher guidance scale value encourages the model to generate images closely linked to the text prompt at the expense of lower image quality. Guidance scale is enabled when guidance_scale
PARAMETER imgen_denoising_end 0.8 # What % of steps to be run on each experts (80/20) (SDXL only)
此外,Kuwa Painter 也可以透過動命令列參數設定,可設定參數如下
Model Options:
--model MODEL The name of the stable diffusion model to use. (default: stabilityai/stable-diffusion-2)
--n_cache N_CACHE How many models to cache. (default: 3)
Display Options:
--show_progress Whether to show the progress of generation. (default: False)
詳細說明可以參考 genai-os/src/executor/image_generation/README_TW.md